- Many widely used VQA benchmarks barely need the image. In roughly a third of the (model × benchmark) pairs, the VLM performs as well or better when the image is replaced by a short caption.
- Visual dependence decreases as VLMs scale up, since a larger backbone answers more from pretraining priors. Raw benchmark accuracy therefore overstates how much VLMs actually see.
- Dependence on the image is a trait of the model family rather than its size. InternVL3.5 shows signs of recalling knowledge from its backbone LM pretraining, and in those cases the image becomes a liability to its reasoning, even hurting accuracy on MMMU.
1Introduction and Motivation
In 2025, AI agents such as Claude Code and Codex were heavily integrated into daily use as they became capable of processing long-context inputs across different modalities. What to feed into the context window has since become not only a question of token expense but also an active area of research. High-resolution images, in particular, take up a large share of the token budget to encode. If they can be replaced with text captions, the savings on context length would be substantial. But doing so requires a prior that image captions alone can match the downstream performance of using the image as input.
The architecture of widely used vision-language models (VLMs) suggests that this prior may hold. Recent VLMs such as InternVL3 and Qwen3-VL pair a pre-trained text-only LLM backbone with a vision encoder, and a growing body of work has questioned how much of a VLM’s downstream capability is genuinely visual versus inherited from its backbone LM. Caption-then-answer pipelines such as PICa and Img2LLM showed early on that replacing the image with a generated caption and handing the result to a strong text LLM was already competitive on VQA. More recent benchmark audits have made the same point from the other direction: MMStar found that roughly half of the items in six widely used multimodal benchmarks can be answered without the image at all, and IsoBench showed that on isomorphic image/text pairs, VLMs systematically perform better when given the text version. MMMU-Pro was constructed specifically to filter out the text-solvable subset of MMMU. Closest to our setting, MIRAGE showed that frontier models will generate detailed image descriptions and reasoning traces even when no image is provided, achieving top rank on a chest X-ray QA benchmark without any visual input at all.
In this post, we systematically evaluate 8 open-weight VLMs on 9 popular visual question answering (VQA) benchmarks under several input conditions. For instance, replacing the original image with a text caption. Here's an example:

The image shows a 3D scene with four objects arranged on a plain, neutral background. Here’s a detailed description of the objects:
- Foreground: There is a large, turquoise cube prominently positioned towards the right side of the image. The cube has smooth, flat surfaces, reflective of a matte or semi-glossy finish, catching light softly.
- Midground: A smaller, shiny, cyan cube is situated slightly to the left and behind the larger turquoise cube. This cyan cube has a glossy surface, giving it a more reflective and metallic appearance.
- Background: Behind and to the left of the two cubes, there is a small, green sphere with a matte finish. Adjacent to the green sphere, there is a small, partial view of a yellow object. This object is mostly obscured, making it difficult to identify its exact shape, but it appears cylindrical or rounded based on the visible portion.
The arrangement suggests a simple still life composition, with a focus on geometric shapes and basic colors. The lighting casts soft shadows, accentuating the spatial relationships between the objects.
A sample question from CLEVR dataset. The default setting allows the VLM to take the original image as input (left), while under different cases a caption replaces the image (right). This caption is generated by InternVL3-14B.
Comparing model performance across these input conditions tells us how much each benchmark actually depends on the image. If an image can be recovered by OCR and read as plain text, a strong backbone LM can solve the task on its own, and such benchmarks may not do much to drive progress in multimodal reasoning. The same stress test also hints at how VLMs approach the task in the first place: are they more comfortable reasoning over text, and if so, do they effectively caption the image internally and then reason over that caption?
2Evaluation Configurations
To investigate the questions above, we ran a controlled stress test across 8 open-weight VLMs, 9 popular VQA benchmarks, and 5 input conditions per question.
2.1 Models
We evaluate three model families spanning sizes from 1B to 30B parameters:
| Family | Models |
|---|---|
| InternVL3 | InternVL3-1B, InternVL3-14B |
| InternVL3.5 | InternVL3.5-1B, InternVL3.5-14B, InternVL3.5-30B-A3B |
| Qwen3-VL | Qwen3-VL-2B, Qwen3-VL-8B, Qwen3-VL-30B-A3B |
All models are run at their default inference settings with a shared system prompt template.
2.2 Benchmarks
We cover nine widely used VQA benchmarks that span synthetic and real-world imagery, perception and reasoning, short-answer and multiple-choice formats:









2.3 Input conditions
For every (model, question) pair we record the model’s answer under five input conditions. The first two vary the type of visual evidence the model is given; the last three are null-input controls that establish what the model can do without genuine visual information.
| Condition | What the model sees |
|---|---|
original | the actual image + the question |
caption | a short text caption generated by InternVL3-14B, in place of the image |
no_images | no image at all, question only |
white | a blank white image + the question |
noise | a random-noise image + the question |
The three null-input conditions (no_images, white, noise) are averaged into a single baseline in the analysis of this post.
2.4 Scoring
Rule-based metrics such as ANLS, BLEU, and exact match break down for modern VLMs: models like Qwen3-VL generate long reasoning traces by default, and string-overlap scores reward surface-level wording rather than correctness. We therefore use LLM-as-judge for every cell. As the primary judge across the full sweep, we use Qwen/Qwen3-30B-A3B-Instruct-2507 due to cost concerns. To validate the judge itself, we re-scored a stratified subset of cells with gpt-5-mini and found roughly 97% agreement with the Qwen judge.
3Dimensions of Interpretation
Accuracy on a VQA benchmark records whether a model answered correctly, but not what it answered correctly from: whether it is from the image, the wording of the question, or knowledge already present in the backbone LM. Before we report results, we would like a few metrics that distinguish these cases.
We treat the three null-input conditions as noisy estimates of the same underlying quantity: the accuracy the model reaches without genuine visual evidence. Their average gives a per-instance baseline,
and every other condition is read relative to it. For a modality m ∈ {original, caption}, the modality gain is
A positive value means input m helped the model on instance i; a negative value means the input hurt relative to receiving no useful visual information at all. Averaged over instances, g_image and g_caption are the image gain and caption gain at the benchmark level.
Derived Metrics
Based on the quantities defined above, we derive three metrics that capture how much each VQA benchmark as well as each VLM relies on the images.
The Modality Differential compares image gain and caption gain on the same instance:
The score is bounded in [−1, +1]. A value near +1 means the image lifts accuracy on this instance and the caption does not. This indicates that the answer depends on something visual that a short text description does not preserve. A value near −1 means that the caption already delivers abundant information while adding the image either does nothing or interferes. A value near 0 means the two inputs are roughly interchangeable for this question.
The caption is a clean description written by a separate model (InternVL3-14B), held fixed across all VLMs we evaluate. The image is therefore judged against a text proxy of controlled quality, isolating whether it adds information that a good description does not already include.
The Caption Substitution of a (model, benchmark) cell is
This is a unitless quantity describing how much accuracy the image retains over a caption, as a fraction of the model’s image accuracy. A value near 0 means a caption recovers as much accuracy as the image, so the image is fully substitutable; a large positive value indicates an irreducibly visual benchmark where the caption cannot replace the image; a negative value means the caption outperforms the image.
Lastly, the Visual Dependence of a model is
It represents the fraction of a model’s correct answers that required the image. Visual Dependence is bounded in (−∞, 1] (typically [0, 1]) and is scale-free, which makes it suitable for comparing models of different sizes on the same benchmark.
Modality Differential, Caption Substitution, and Visual Dependence are the three quantities that we use to interpret behaviors of VLMs when processing different modalities.
4How Visual are VQA benchmarks
We now apply the three quantities (Modality Differential, Caption Substitution, and Visual Dependence) defined in §3 to the evaluation results from the sweep in §2.
4.1 Benchmarks differ sharply in how much they depend on the image
We plot each benchmark’s Visual Dependence (the fraction of the model’s accuracy that the image is responsible for) against its Caption Substitution (how much accuracy the image retains over a caption), with all numbers averaged across the eight models.
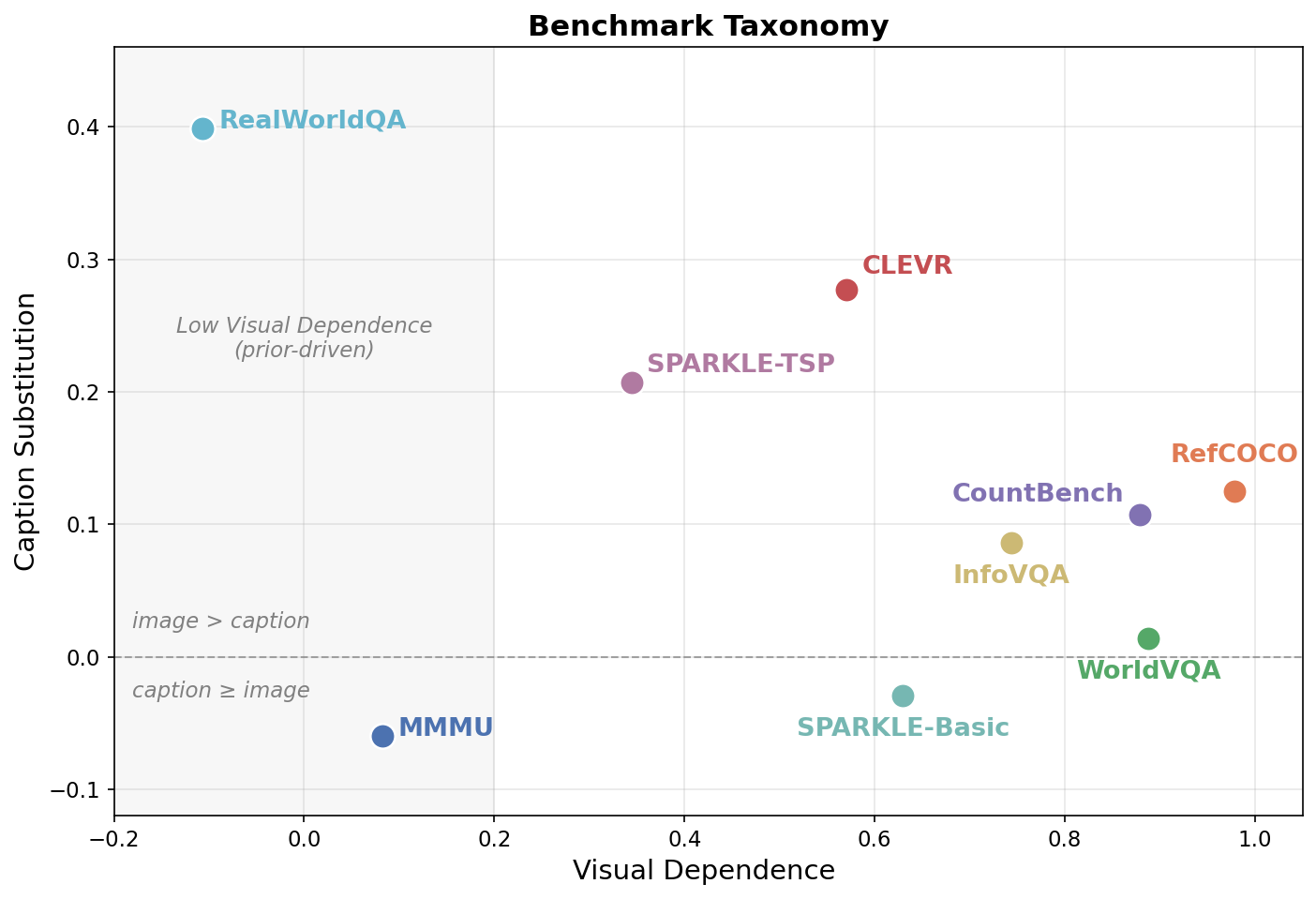
y = 0 separates benchmarks where the image still beats a caption (above) from those where a caption matches or outperforms the image (below). The shaded band on the left marks benchmarks with low Visual Dependence, where the image barely helps over no image at all.Along the Caption Substitution axis, most of the VQA benchmarks sit close to zero, which suggests that replacing images with a static caption can recover nearly all of VLMs' accuracies. Notably, on MMMU and SPARKLE-Basic, using the captions slightly outperforms the original images. Benchmarks such as RealWorldQA, CLEVR, SPARKLE-TSP and RefCOCO achieve comparatively higher Caption Substituion, whose images are harder to be transcribed. Along the Visual Dependence axis, VLMs' performance on RefCOCO, WorldVQA, and CountBench depend almost entirely on the images. On the other hand, accuracies on MMMU and RealWorldQA barely changes even when the image is hidden.
We take a useful VQA benchmark to be one whose Visual Dependence is non-trivially positive: if accuracy does not rise when the image is provided, then a model’s correct answers cannot be credited to visual reasoning in the first place. Among the benchmarks that pass this bar, Caption Substitution tracks the type of visual content being tested.
4.2 Per-benchmark Modality Differential
Modality Differential collapses the two axes of Figure 1 into a single bounded number per benchmark. It is large and positive when the image lifts accuracy on an instance and the caption does not, which corresponds to the upper-right of Figure 1 (high Visual Dependence and high Caption Substitution). It decays toward zero along the bottom of the plot, where Caption Substitution is near zero and the two inputs are interchangeable (WorldVQA, RefCOCO, CountBench), and it turns negative where the caption does more than the image (MMMU, SPARKLE-Basic). A high Modality Differential therefore signals two things at once: that the image is contributing meaningfully and that captions fail to substitute for it.
4.3 Low Visual Dependence signals data leakage
Taking a closer look at the Visual Dependence for each benchmark, it turns out to vary greatly across VQA benchmarks.
| Benchmark | acc(original) | acc(no_images) | Visual Dependence |
|---|---|---|---|
| RefCOCO | 73.5 | 1.6 | 97.8% |
| WorldVQA | 7.2 | 0.8 | 88.8% |
| CountBench | 78.6 | 9.5 | 87.9% |
| InfoVQA | 66.0 | 16.9 | 74.4% |
| SPARKLE-Basic | 56.5 | 20.9 | 63.0% |
| CLEVR | 88.8 | 38.2 | 57.0% |
| SPARKLE-TSP | 7.2 | 4.8 | 34.5% |
| MMMU | 46.5 | 42.7 | 8.3% |
| RealWorldQA | 5.5 | 6.1 | −10.7% |
Per-benchmark Visual Dependence averaged across the VLMs. A higher percentage means more of the benchmark’s correct answers required the image.
A low Visual Dependence is likely due to answer leakage: VLMs are able to recover the right answers from the question text alone. MMMU and RealWorldQA stands out of the nine VQA benchmarks we evaluate. At the other extreme, RefCOCO, WorldVQA, and CountBench collapse without the image. One limitation is that for certain benchmarks, VLMs' original accuracies are very low (below 10%) and Visual Dependence might inflate the gap when images are removed. We therefore list the raw accuracies under both input conditions, and would like to emphasize that MMMU demonstrates low Visual Dependence despite a 46.5% original accuracy. This is consistent with the findings of MMStar and MMMU-Pro. We further trace which VLMs show stronger evidence of it in the case study of §5.3.
5VLM Capability Evaluation
In this section, we evaluate the metrics by aggregating over each VLM, averaged across the 9 benchmarks. This helps us to interpret how each VLM in our set processes its inputs.
5.1 Visual Dependence drops with model scale
We measure the Visual Dependence across all eight models averaged over all benchmarks.
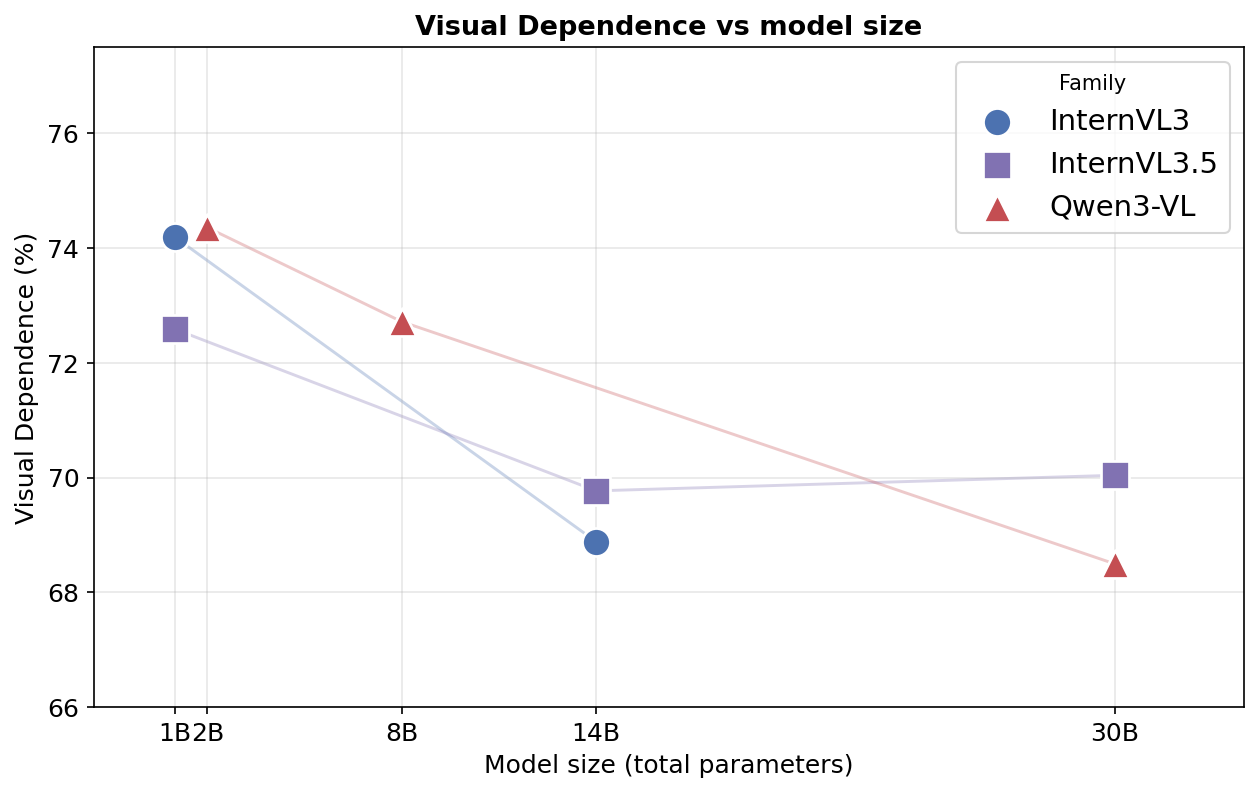
Visual Dependence is varies between 68% and 75% across all eight models. There’s a trend that it scales inversely with model scale, dropping from 73-74% for 1B and 2B models to 68-70% for 30B variants. We hypothesize that this is because larger models have a larger LLM backbone, which resolves a larger share of questions from world knowledge alone, leaving a smaller residual share for the image to actually contribute to.
5.2 The image-vs-caption lean is family-specific
Aggregating Modality Differential and Caption Substitution across the 9 benchmarks gives a single number per model along each axis. They separate the three VLM model families.
| Model | mean Modality Differential | mean Caption Substitution |
|---|---|---|
| InternVL3.5-1B | −0.04 | −0.37 |
| InternVL3.5-30B-A3B | +0.01 | −0.31 |
| InternVL3.5-14B | +0.03 | +0.05 |
| InternVL3-14B | +0.03 | +0.02 |
| InternVL3-1B | +0.05 | +0.03 |
| Qwen3-VL-2B | +0.07 | +0.12 |
| Qwen3-VL-30B-A3B | +0.10 | +0.28 |
| Qwen3-VL-8B | +0.10 | +0.29 |
In terms of Modality Differential and Caption Substitution, three model families show a clear trend. The two move together: both are high when a model leans on the image and low (or negative) when a caption serves it just as well. The Qwen3-VL models turn out to be the most image-leaning, while the InternVL3.5 models are the least. This suggests that VLM architecture and pre-training decisions may matter more than scaling for how models treat image versus caption inputs.
5.3 Case study: which VLMs benefit from data leakage
In §4.3 we saw that MMMU may suffer from answer leakage. Here we perform a case study on MMMU and report the Visual Dependence as well as the Caption Substitution of all VLMs.
| Model | acc(original) | Visual Dependence | Caption Substitution |
|---|---|---|---|
| InternVL3.5-30B-A3B | 45.3 | −5.1% | −26.2% |
| InternVL3.5-14B | 48.6 | −2.3% | −19.2% |
| InternVL3.5-1B | 27.3 | −28.9% | −45.1% |
| InternVL3-1B | 34.4 | +5.5% | +1.9% |
| Qwen3-VL-2B | 44.8 | +18.6% | +1.2% |
| Qwen3-VL-8B | 56.2 | +21.1% | +4.9% |
| Qwen3-VL-30B-A3B | 58.0 | +19.9% | +5.2% |
| InternVL3-14B | 57.4 | +14.7% | +7.5% |
VLM Visual Dependence and Caption Substitution results on MMMU.
InternVL3.5 models stand out from the rest. Their negative Visual Dependence suggests that they recover MMMU answers from knowledge absorbed during pre-training rather than from the image. Meanwhile, the strongly negative Caption Substitution suggests that in cases when these models draw knowledge from pre-training, their vision-encoders may stand in the way of backbone LMs to reason for the right answer.
Qwen3-VL models show the mirror image, scoring positive on both metrics: the image lifts their accuracy over both a no-image baseline and a caption. While we do not claim that Qwen3-VL is free of data leakage, these two metrics surface less evidence of it.
6Discussion
Aggregated over benchmarks, our metrics suggest that accuracy on a multimodal benchmark does not directly mean there’s evidence of multimodal reasoning. Several widely used VQA benchmarks turn out to be answerable from a short caption alone, which means a leaderboard climb on them can come entirely from a stronger backbone LM. In terms of those tasks where images do contribute, the kind of contribution is not uniform: text-transcribable tasks give most of it back through a caption, while relational and spatial tasks do not. How “visual” the VQA benchmarks are is therefore a two-fold question: whether the image matters at all, and whether a caption can substitute for it.
How a VLM uses its vision encoder turns out to be more a matter of architecture and pre-training than of scale. Visual Dependence decreases as with the scaling of VLMs, likely because a larger backbone LM answers more questions from knowledge absorbed during pre-training. The observation that image-vs-caption lean splits cleanly by model family further supports this claim. We hypothesize that this reflects a failure to connect the backbone LM with their vision-encoders. The vision input is present but does not productively support downstream reasoning. When this happens, accuracy on a canonical benchmark stops measuring the visual capability the benchmark was designed to test. Further, our case study on MMMU (§5.3) shows that VLMs may draw knowledge from pre-training, and in these cases the vision inputs instead become distractors of the reasoning process. How much a VLM leans on its backbone LM is therefore a question worth answering during evaluation.
One practical application of the insights is to save budget of the VLM context window. Since high-resolution images are expensive to encode, replacing them with captions on benchmarks with low Caption Substitution — where a caption loses the model almost no accuracy — can save thousands of tokens each. The savings would be more effective for long multi-turn conversations or video reasoning. One limitation is that this may only hold for tasks that are easy to transcribe.
7Related Work
Replacing an image with a text description and handing it to a language model is studied by many previous work. We hope to identify them here to the best of our knowledge and hope this post can be used as a pointer to related topics.
Caption-then-answer pipelines such as PICa and Img2LLM showed that a strong text-only LLM fed with a generated caption, is already competitive on VQA without end-to-end vision–language training. We revisit that substitution diagnosticly: rather than asking whether a caption pipeline can match a VLM, we ask, per instance, how much of a VLM’s own accuracy survives when its image is swapped for a caption.
A parallel line of work audits whether multimodal benchmarks actually require the image. MMStar found that a large fraction of items across six popular benchmarks are answerable with no visual input and proposed cleaner splits; IsoBench showed that, given isomorphic image/text representations of the same problem, VLMs systematically score higher from the text form; and MMMU-Pro hardened MMMU by filtering out the text-solvable subset and adding harder distractors. More directly, Lan et al. ask whether VLM benchmarks test vision at all: they find that hiding most of an image’s tokens barely hurts accuracy.
A complementary line probes how VLMs weigh modalities internally. Sun et al. show that the same text rendered as an image suppresses step-by-step reasoning. Models emit far shorter answers and skip computation, which helps explain why several of our models reason better from a caption than from the image itself. Hua et al. show that when image and text disagree, VLMs systematically favor one modality, traced to specific “router” attention heads.
Closest in spirit, MIRAGE showed that frontier models will generate detailed image descriptions and confident answers even when no image is provided, topping a chest-X-ray QA benchmark blind. Our null-input controls (no-image, blank-white, and random-noise) are designed to surface exactly this behavior in open-weight VLMs and to separate it from genuine visual gain.
Citation
If you find this post useful, please cite it as:
@misc{fu2026seeing,
title = {Seeing Is Not Reasoning: How VLMs and Their Benchmarks Lean on Text},
author = {Fu, Harvey Yiyun and Yang, Chenghao and Chang, Ting-Yun and
Wang, Zhaowei and Wu, Zhaofeng and Zhou, Jiawei and Fu, Deqing},
year = {2026},
month = {May},
url = {https://harvey-fin.github.io/seeing-is-not-reasoning/}
}